
SEO Workshop: Robots.txt
Terwijl de sitemap opgeeft welke pagina’s geïndexeerd mogen worden geeft de robots.txt aan welke pagina’s we niet willen indexeren. Bemerk dat beide bestanden publiek vindbaar zijn (ook voor hackers!) en geen garanties bieden.
De robots.txt is een essentieel onderdeel voor SEO.
We plaatsen het in de root directory van onze website naast de sitemap.xml.

Op elke site kan je robots.txt opvragen als volgt: www.mijnsite.be/robots.txt
twitter: https://twitter.com/robots.txt
facebook: https://www.facebook.com/robots.txt
Wikipedia: https://en.wikipedia.org/robots.txt
Learningfever: https://www.learningfever.be/robots.txt
Geen garanties
Robots.txt is een advies.
Sommige spiders negeren dit bestand en hackers gebruiken het om te weten welke pagina’s je wil afschermen!
Als je pagina’s wil afschermen gebruik je best een login barriere of een IP Whitelisting. Dergelijke pagina’s kunnen niet zomaar bezocht worden en kunnen dus niet geïndexeerd geraken. Denk wel goed na welke pagina’s je achter een login wil verstoppen want de online winkel willen we natuurlijk toegankelijk houden voor niet-ingelogde bezoekers…
Goede spiders zoeken naar de robots.txt voordat ze crawlen. Als ze dit bestand vinden houden ze hier (meestal) rekening mee. Het voorkomt echter niet dat de URL geïndexeerd kan worden.
Voorbeeld bestand
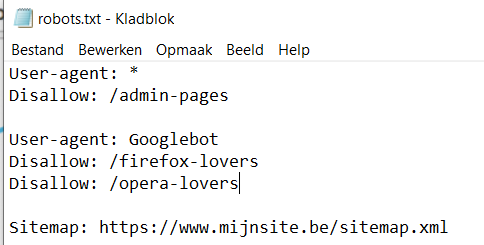
Hoe interpreteer je de inhoud van dit voorbeeld bestand?
Bemerk: liefst geven we aan dat bepaalde folders niet toegankelijk zijn en doen we dit niet voor individuele bestanden. Dit maakt het moeilijker voor hackers ook om de bestandsnamen te kennen.
Ontwikkeling Website
Bemerk dat je bij het ontwikkelen van je website kan aangeven dat je niets wil indexeren.
Je gebruikt dan de code:
User-Agent: *
Disallow: /
Vergeet het dan ook niet te veranderen voor je live gaat met je website 🙂
Commando’s bij Robots.txt
- user-agent: welke crawler (elke zoekmachine heeft een eigen crawler naam)
- crawl-delay 10 (om de 10sec 1 pagina) -> het vertragen van specifieke crawlers mindert de belasting op onze webserver (de crawler van Google ondersteunt dit niet) -> crawl rate kan ingesteld worden op de oude google search console
- disallow: een folder of pagina die niet geïndexeerd mag worden
- allow: een folder of pagina die wel geïndexeerd mag worden (om een disallow plaatselijk ongedaan te maken)
De zoekmachine kijkt of robots.txt aanwezig is.
Zo ja, kijkt deze naar de suggesties en beperkingen.
Zo nee, dan crawlt deze zonder beperkingen.
Indien een “error” plaatsvindt weet deze niet of een robots.txt bestaat en gaat deze niet crawlen om ongewenste indexering te vermijden.
Robots.txt vs Meta-tag robots
Als alternatief op robots.txt bestaat een meta tag. Dit kan je op een specifieke webpagina toevoegen om te vermijden dat die ene pagina geïndexeerd zou worden. We kunnen de crawler niet specifieren en geen crawl delay opgeven. Maar we vermijden ook dat we pagina‘s proberen te verstoppen door een overzicht op te geven in een publiek leesbaar bestand (wat robots.txt doet).
<meta name="robots" content="noindex">
We kunnen ook opgeven dat we we niet willen dat hyperlinks vanop de huidige pagina gevolgd worden.
<meta name="robots" content="noindex, nofollow">