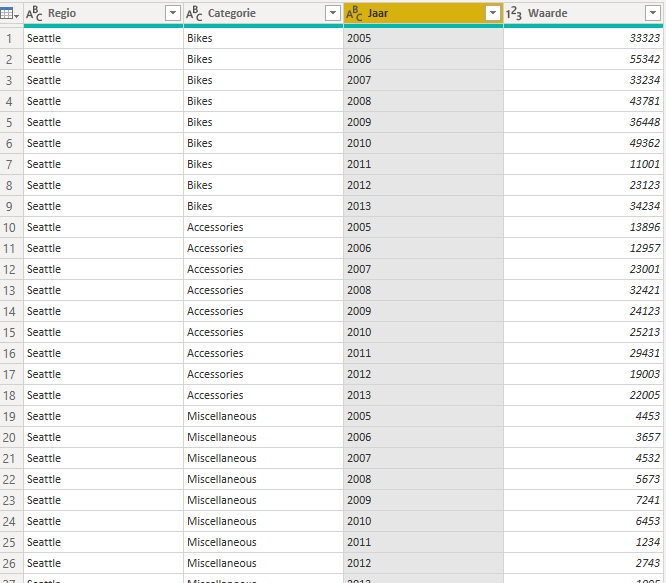
PBi_Data zuiver maken
ENTITEITEN BENOEMEN (header aanpassen)
Ten eerste zie je momenteel dat alle kolommen benoemd zijn, gewoon met een cijfer. Column 1, Column 2 enzoverder… Dit is niet erg handig.
Een betere kolomnaam zou de tweede rij zijn.
Daar zie je Country, Subject Descriptor, Units, Scale enzoverder.
Om van deze rij de kolomnaam te maken zijn er 2 stappen nodig.
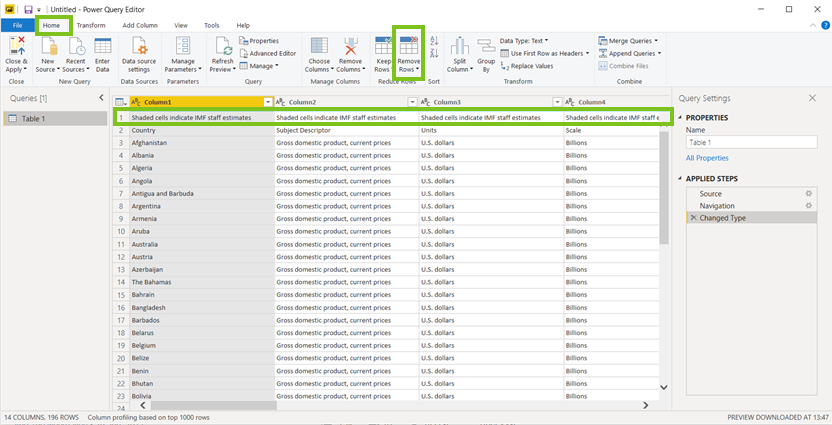
De eerste stap is het weghalen van de rijen die informatie bevatten die we niet nodig hebben… Daarna gaan we de nieuwe bovenste rij transformeren naar de header van de tabel.
Om de eerste rij te verwijderen, ga je eerst naar de Home-tab, en dan naar Remove Rows.
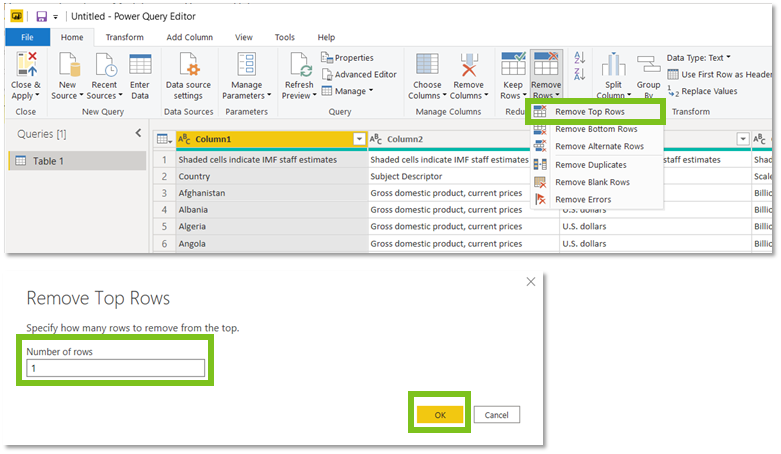
We kiezen dan ‘Remove Top Rows’ en geven het aantal rijen in dat we willen verwijderen. We willen hier maar 1 rij weghalen, dus we geven 1 in en drukken op OK.
We zien nu dat onze rij met Country en dergelijke als eerste staat. Nu gaan we van deze eerste rij de Header maken.
We zitten nog steeds in de Home-tab, en selecteren nu de optie: ‘Use First Row as Header‘.
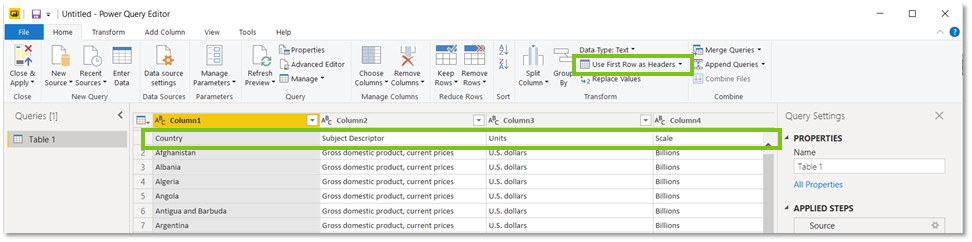
We zien dat onze kolommen nu een betekenisvolle naam hebben…. Maar hierdoor zijn we nog steeds niet volledig klaar…
ONNODIGE KOLOMMEN VERWIJDEREN
Met de pijltjes links en rechts kan je door de kolommen navigeren.
De Country, Subject Description, Units en Scale kolom zijn OK, maar de country/Series-specific Notes hebben we niet nodig…. Om die te deleten, moeten je hem gewoon selecteren en dan, nog steeds in de Home-tab, ‘Remove Columns‘.
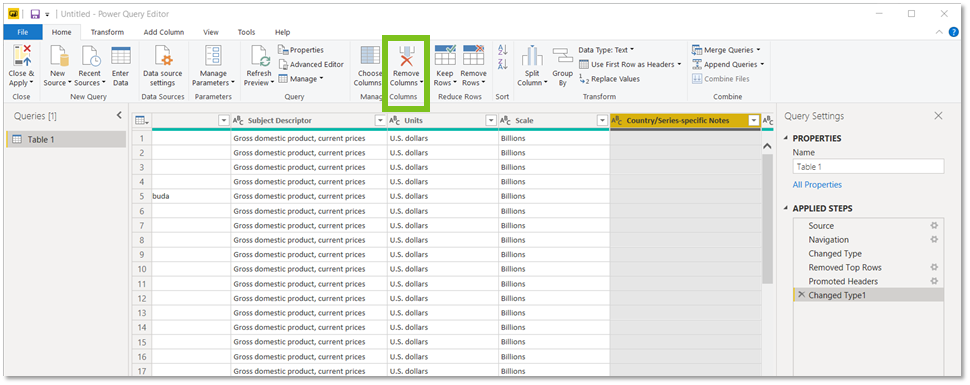
Kijk of er nog kolommen zijn die weg mogen…
De jaartallen mogen blijven, maar daar gaan we zometeen wel nog even op terugkomen, maar Column 14, mag ook weg….
HERHALENDE GROEPEN WEGWERKEN
Laten we nu even kijken naar de verschillende kolommen met jaartallen. Ik denk dat de manier waarop deze momenteel weergegeven worden niet de beste is…
Zou het niet beter zijn als we dat over zouden kunnen zetten in slechts 2 kolommen?
Een kolom, ‘years‘ genaamd, met het overeenkomstige jaar in verschillende rijen van die kolom en één kolom met de overeenkomstige ‘BNP‘-data?
Ik denk het wel, en om dit te doen, moeten we eigenlijk gewoon de jaarkolommen omzetten naar rijen.
We doen dit door de eerste jaarkolom te selecteren, dan de shift-toets (hoofdletter) in te drukken en de laatste jaarkolom te selecteren. Dan selecteren we de Transform-tab ipv de Home-tab, en klikken we op Unpivot Columns-functie.
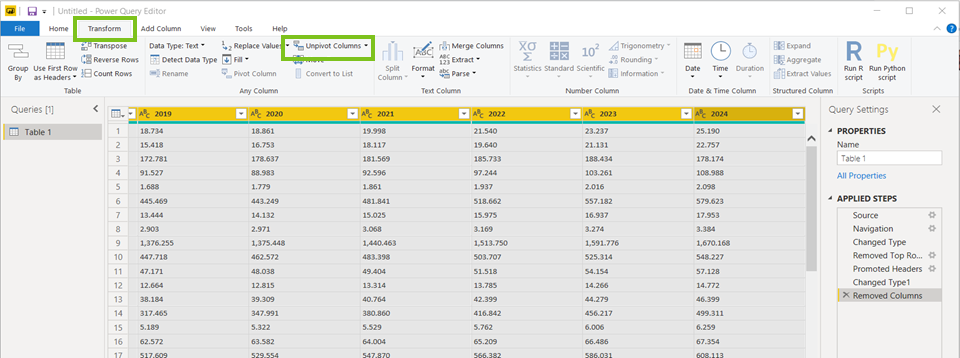
Dan krijgen we dus dit…
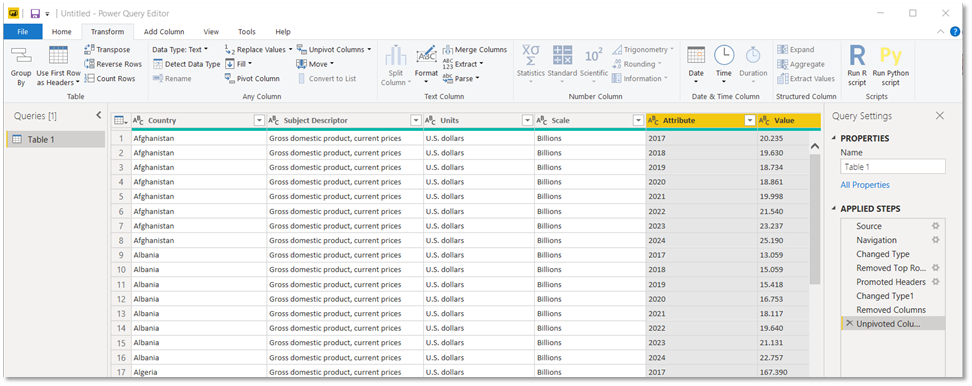
En zoals je ziet hebben we de verschillende kolommen omgezet naar één kolom met voor elk jaar één rij, en één kolom met de overeenkomstige BNP-waarden.
NAMEN VAN DE HEADERS AANPASSEN
Nu hebben de headers van deze 2 kolommen nog niet de gewenste namen. We gaan deze aanpassen:
- Dubbelklik op de Attribute kolom en verander de naam in Year
- Doe hetzelfde met de Value kolom en verander die naam in Bruto national product (of GDP als we in ‘t Engels willen blijven)
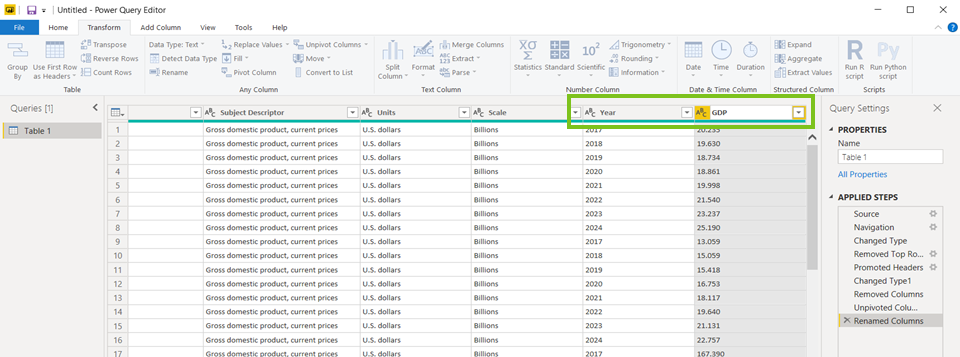
N/A’s EN LEGE VELDEN WEGHALEN / FILTEREN
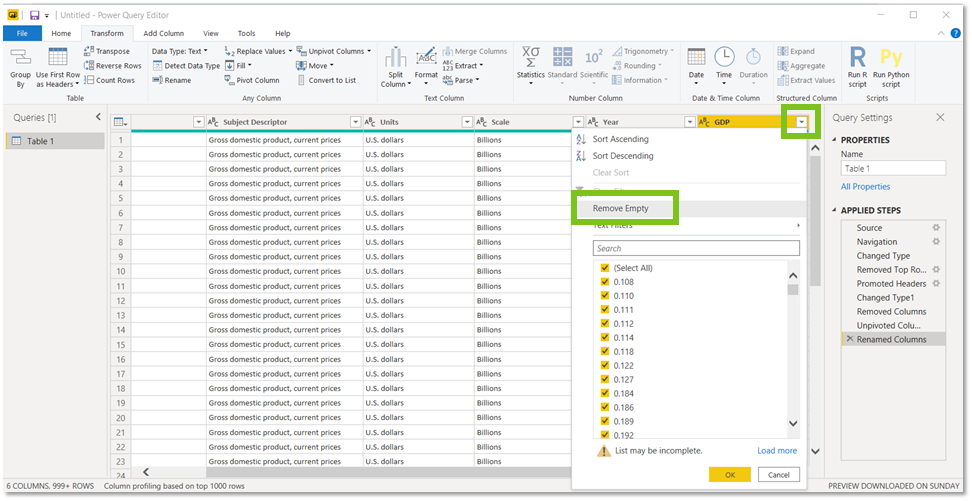
Nu gaan we kijken of we voor alle rijen uit de GDP-kolom ook daadwerkelijk data hebben, want we willen uiteindelijk enkel de belangrijke informatie invoeren in ons data-model.
Om dit te doen klikken we op het pijltje naast de GDP header, scrollen naar beneden, en kijken of er daadwerkelijk n/a’s voorkomen in deze kolom. Hier hebben we er nu geen, maar als er zouden zijn, kunnen we gewoon de checkboxen uitklikken.
We kunnen ook een ‘remove Empty’-filter toepassen. Dit zou in hetzelfde resulteren. Zo zijn we zeker dat lege velden niet meegenomen worden richting ons data-model.
BELANGRIJK
Filteren in de Power Query Editor verandert de data die geladen wordt in PowerBi. Als we straks filters gaan toepassen in ons ‘Rapportzicht’ of in ons ‘Gegevenszicht’ worden die enkel toegepast op de visualisaties. Ze veranderen de onderliggende dataset niet.
DATA_TYPE AANPASSEN
Wat we nu nog gaan doen is het data-type van deze kolom veranderen.
Wat houdt dit in en waarom zouden we dat doen?
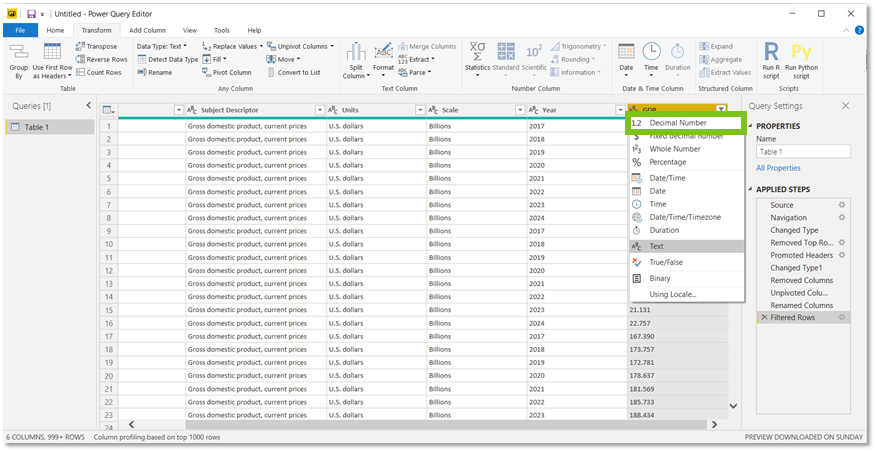
Wel, als je op die ABC-picto klikt, zie je dat die picto overeenstemt met ‘Text’. Dit betekent dat de waarden in deze kolom geconfigureerd zijn als tekst, wat eigenlijk niet correct is.
We gaan dit veranderen. Dat is heel simpel. We kunnen in deze lijst een ander data-type selecteren, Decimal number bijvoorbeeld. We zien dan het pictogram naast de naam verandert.
Wat nu als je het datatype van verschillende kolommen wilt veranderen?
Dan kan je, zoals we daarstraks gedaan hebben met de verschillende jaartallen, door middel van de shift-toets de verschillende kolommen selecteren en dan, nog steeds in onze Transform-tab, ‘Detect Data Type’ aanklikken.
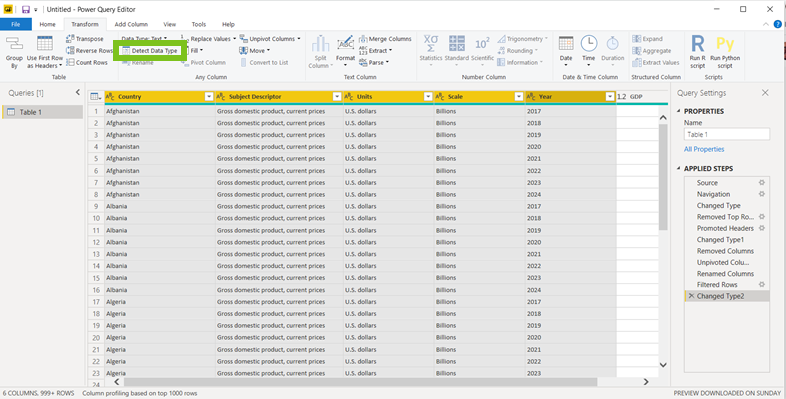
We zien dat voor de kolommen Country, Subject Descriptor, Units en Scale, er niets veranderd is. Dat is logisch want het gaat hier daadwerkelijk om tekst-data; maar dat het datatype van ‘Year’ wel veranderd is naar ‘whole number‘, wat OK is voor het moment.
En dan zijn we rond met onze voorbereiding in de Query Editor, klaar om de data toe te voegen aan ons datamodel….
De volgende stap is nu dus om deze zuivergemaakte data in ons eigenlijk datamodel toe te voegen en vizualisaties te maken…
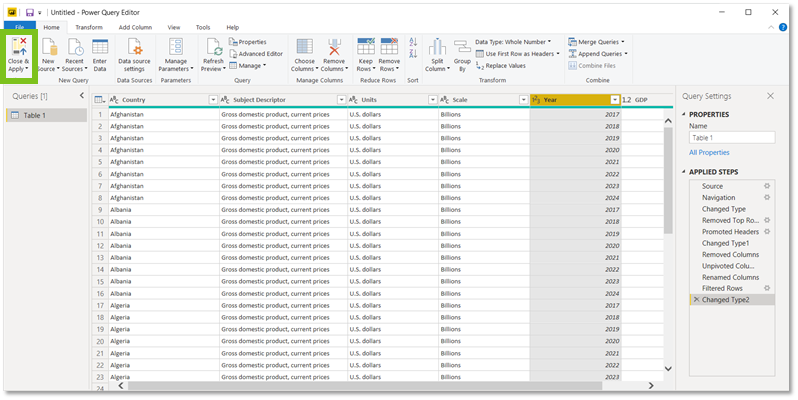
Om dit te doen moeten we uit onze Query Editor gaan en dat doen we door terug naar onze Home-tab te gaan en daar klik je op ‘Close & Apply‘.
SAMENGEVAT
- Zorg ervoor dat de juiste gegevenstypen worden gebruikt.
- Verwijder onnodige kolommen en rijen.
- Vermijd herhaalde waarden.
- Vervang numerieke kolommen door metingen.
- Verminder kardinaliteiten. (uitbreiding)
- Analyseer de Modelmetadata. (uitbreiding)
- Vat gegevens Waar mogelijk samen.
EXTRA (niet nodig voor huidige oefening)
Soms ziet een tabel-ontwerp er goed uit voor ons mensen, maar is het niet optimaal voor geautomatiseerde queries. Wil je dit testen, trek dan de file ‘Test-transpose’ binnen die je HIER vindt.
Volgende afbeelding is daar een voorbeeld van:
TRANSPONEREN
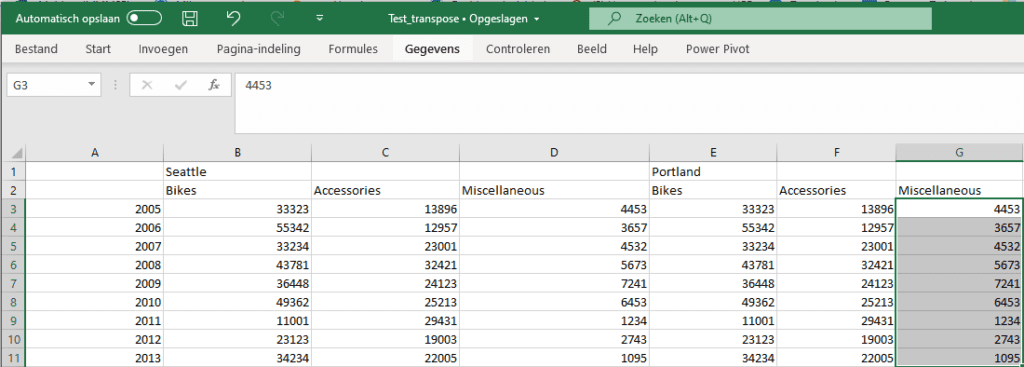
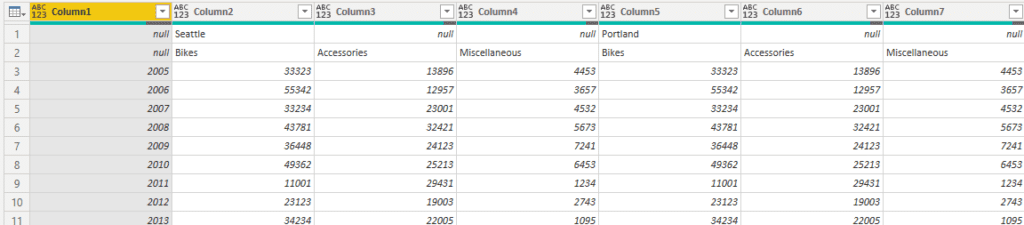
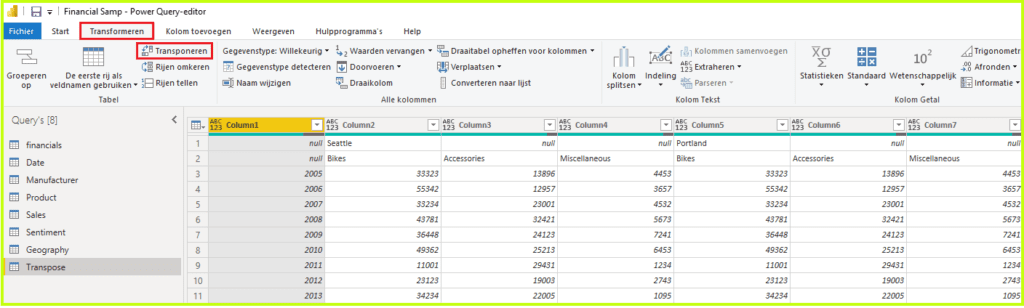

De volgende stappen die ik doe:
- Start-tabblad > De eerste rij als veldnamen gebruiken: de jaren komen in de verschillende kolomheaders te staan.
- Benoem kolom 1 en 2, met respectievelijk Regio en Categorie

Nu zal je zien dat in de kolom ‘Regio’ null-waarden aanwezig zijn. Deze kan je invullen.
- Transormeren-tabblad > Doorvoeren > Omlaag: de ontbrekende waarden worden ingevuld naar het voorbeeld. In onze query worden de null-waarden vervangen door de waarde die boven de respectievelijke null staat. Je kan ook in de andere richting werken, ttz, invullen naar boven toe.
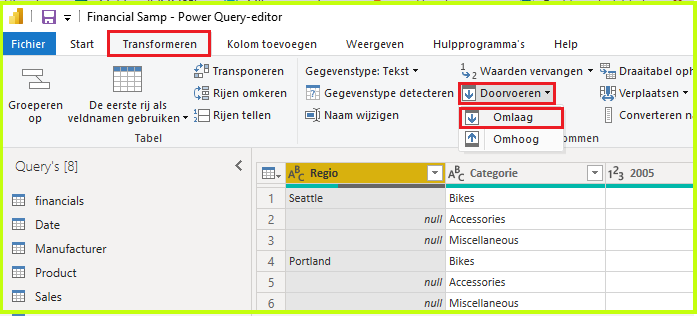
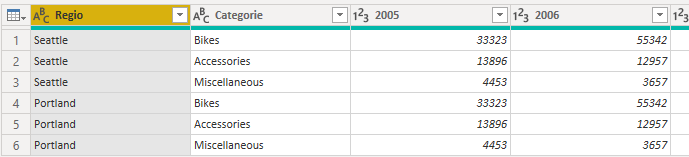
Nu kan je opnieuw de draaitabel opheffen om van de verschillende jaren / waarden 2 kolommen te maken.