
PBi_Bottom-up analyse
Een andere veel gebruikte methode is de ‘bottom-up-analyse‘.
Hierbij wordt vertrokken van bestaande informatie om ons model te ontwerpen.
Deze methode voorkomt 3 problemen die nogal eens kunnen optreden:
- Overbodige gegevens
- Inconsistentie
- Inefficiëntie
We onderscheiden in een bottom-up-analyse verschillende soorten gegevens:
- Constante gegevens: Dit zijn data die zelden wijzigen.
Vb naam / adresgegevens van het bedrijf of BTW% - Procesgegevens: Gegevens die kunnen worden afgeleid, berekend uit andere gegevens.
Vb bedrag of totaal - Elementaire gegevens: alle andere gegevens, eveneens repeterende, herhalende gegevens.
Hoe gaan we nu te werk bij een bottom-up-analyse. Laten we eens kijken naar onderstaande bestelbon en de gegevens die we hieruit kunnen halen.

We zetten al deze gegevens in een tabel, onder de 0de normalisatievorm (nv).

We gaan nu opsplitsen door een tweede tabel te maken met de repeterende groep, plus een kopie van de primaire sleutel, die we als externe sleutel toevoegen.
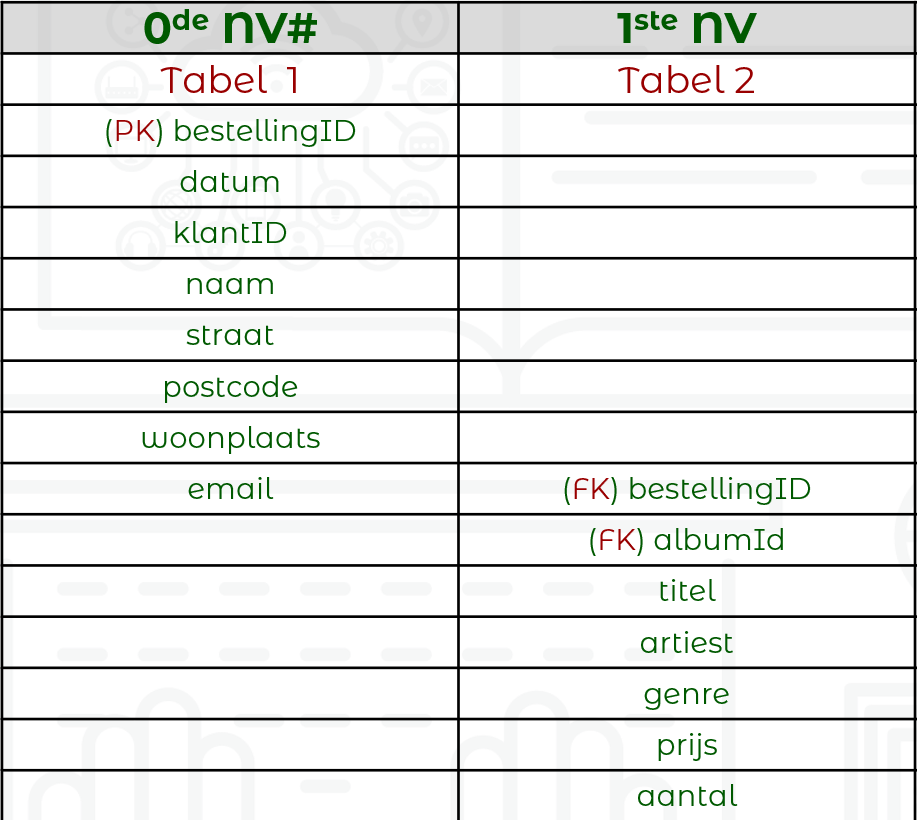
We gaan verder met opsplitsen, voegen een derde tabel toe met een kopie van de samengestelde sleutel en de bijhorende attributen.
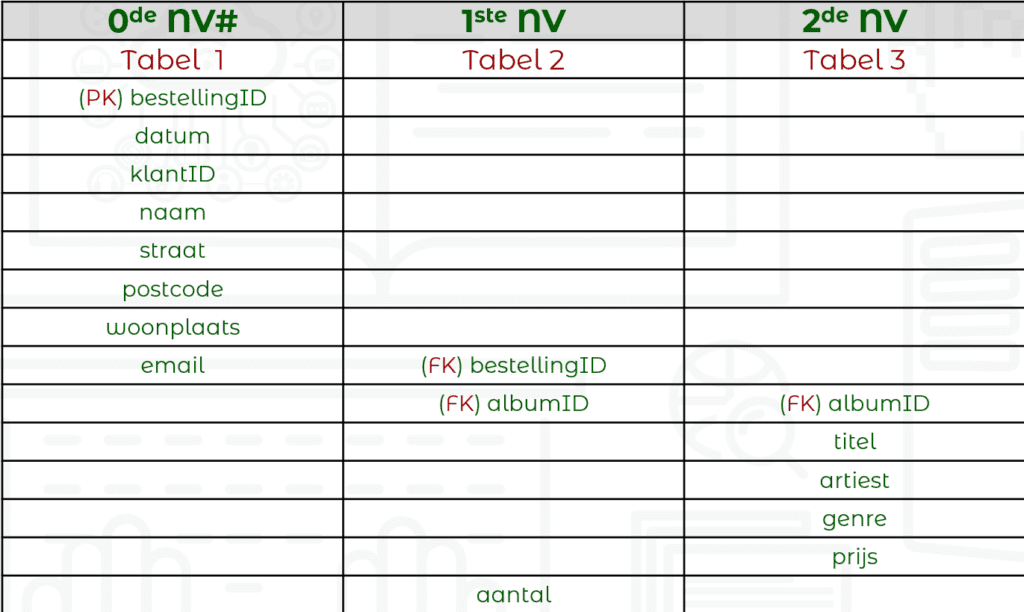
We kijken of we nog verder kunnen opsplitsen, maken eventueel een vierde (vijfde, zesde) tabel met de nodige splitsingen. We maken ook de koppelingen tussen de tabellen met primaire en verwijzende (externe) sleutel. We kunnen nu ook de verschillende entiteiten benoemen.
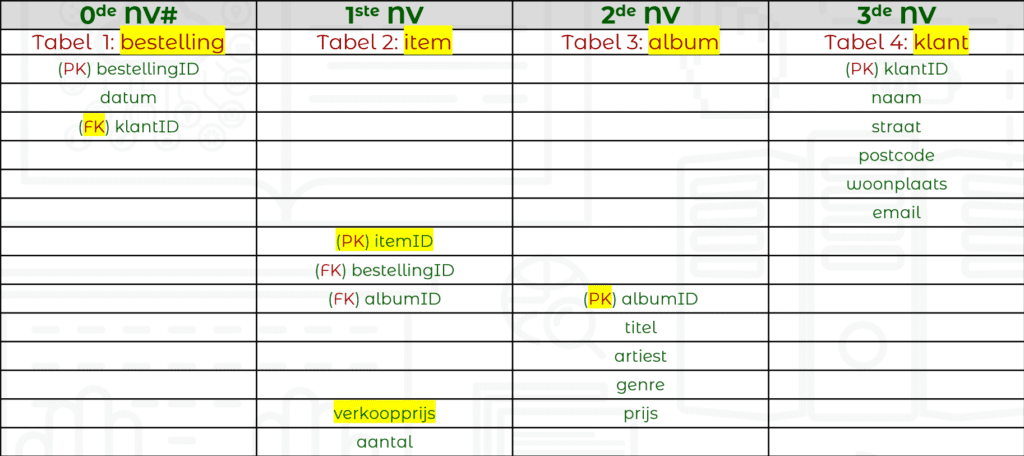
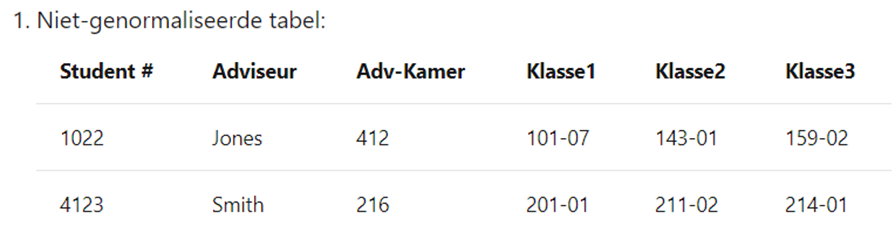
HERHALENDE GROEPEN
In onderstaand voorbeeld (Niet-genormaliseerde tabel) zien we dat één student verschillende ‘Klassen’ heeft (Klasse1, Klasse2, Klasse3). Deze repeterende velden zijn een indicatie van ontwerpproblemen.
Tabellen mogen, in tegenstelling tot spreadsheets, slechts 2 dimensies hebben.
We doen er best aan deze verschillende ‘Klasse‘ in een afzonderlijke tabel op te nemen.
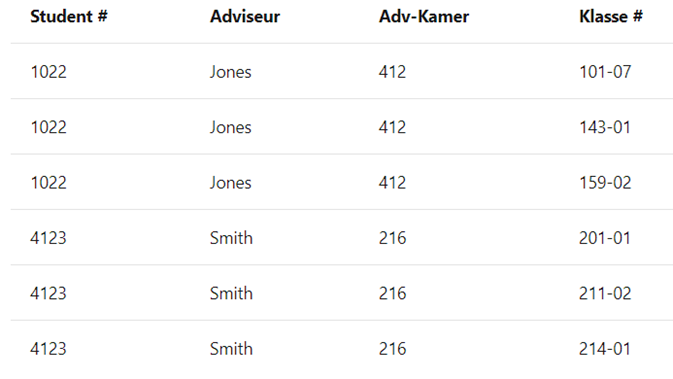
Student 1022, die voorkomt in klasse1, 2 en 3 wordt nu 3 keer weergegeven zoals je kan zien, maar de kolom ‘Klasse‘ komt maar 1 keer voor.